









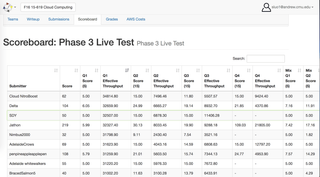
Big Data Analytics System en la nube de AWS(Java, AWS, MapReduce, HBase, MySQL)
◈ Desarrollé un servicio web tolerante a fallas de alto rendimiento para analizar más de 1TB de datos de Twitter con 4 consultas diferentes. Datos brutos filtrados y transformados de AWS S3 a HBase y MySQL utilizando MapReduce. Se utilizaron las políticas de equilibrado de carga y escalado automático a través de AWS Java API y contenedores Docker para la configuración.
◈ Aplicó más de 5 métodos para optimizar la base de datos y logró un promedio de 27800 QPS (consultas por segundo) en un conjunto de datos que contiene aproximadamente 200 millones de registros con recursos muy limitados.
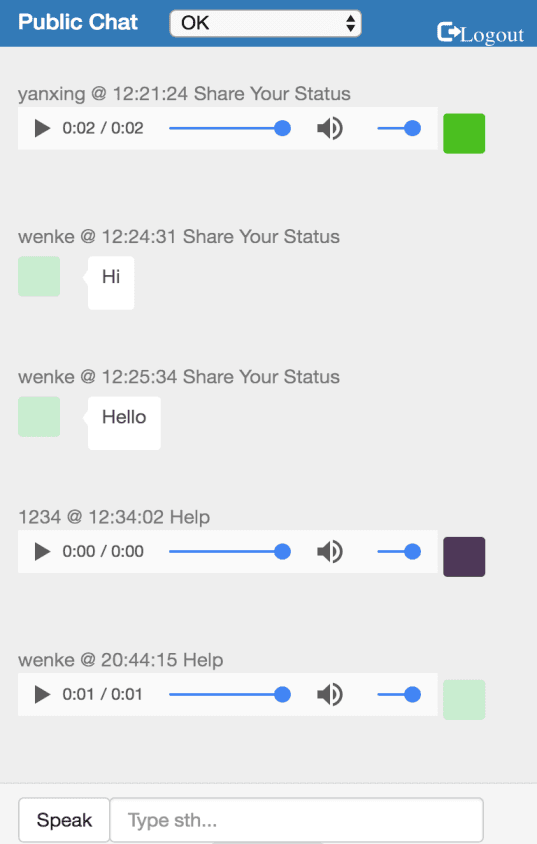
Red social de emergencia RESTful(Node.js, AngularJS, MongoDB, Heroku)
◈ Dirigió un equipo de 5 personas para desarrollar una aplicación web en tiempo real para la comunicación en casos de desastres naturales.
◈ Desarrollé una aplicación web potenciada por Node.js con AngularJS, MongoDB y la implementé en la nube de Heroku.
◈ Metodología mixta seguida de Scrum y Kanban con prueba unitaria, programación de pares e integración continua.
◈ Desarrollé una función de chat de voz para mejorar la comunicación en tiempo real y la técnica de decodificación base64 aplicada.

Servicio de ajuste de controladores de precios dinámicos
En este proyecto, implementé un servicio de ajuste de controladores de precios dinámicos con Kafka y Samza para simular y procesar múltiples flujos de datos de ubicación y eventos del controlador UBER en forma de transmisión.
Guión
PittCabs es una próxima aplicación privada de taxi / viaje compartido. Usted está contratado para implementar la parte central del servicio, la de hacer coincidir las solicitudes de los clientes con los controladores disponibles. Las aplicaciones de aclamación de Cab como Uber hacen que el controlador envíe actualizaciones de posición aproximadamente cada 5 segundos, lo que forma una gran cantidad de datos. Una forma de manejar las actualizaciones de posición es seguir actualizando un almacén de datos tradicional (MySQL / Hbase) con las posiciones y, cuando entre la solicitud de un usuario, buscar la ubicación del conductor y hacer coincidir el controlador más cercano con el cliente. Este enfoque no es muy escalable incluso con la fragmentación y / o la duplicación y es un desperdicio, ya que una vez que el conductor se ha movido a una nueva posición 5 segundos después, los datos antiguos son inútiles. Al estar bien informado sobre las últimas tecnologías en la nube, usted decide utilizar el modelo de computación de procesamiento de flujo ya que se ajusta muy bien al caso de uso.
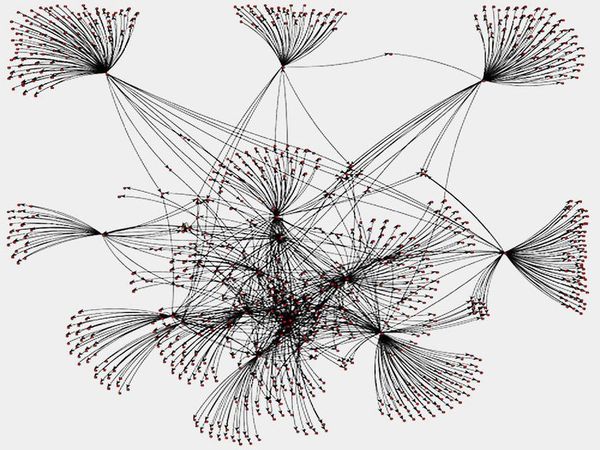
PageRank para Twitter Social Graph
(Scala, Spark, GraphX)
En este proyecto, utilicé Spark y GraphX para calcular el valor de PageRank para cada nodo en el gráfico social de Twitter.
Programación multi-threading y consistencia
Con el advenimiento de Internet, el comercio electrónico y las redes sociales, las organizaciones se enfrentan a una explosión masiva en la cantidad de datos que se deben manejar a diario. No es raro en estos días que las grandes compañías de Internet tengan que procesar petabytes de datos diariamente. Almacenar, procesar y analizar esta información es un desafío enorme y ha superado las capacidades de almacenamiento, memoria e informática de una sola máquina. Requerimos sistemas de almacenamiento de datos distribuidos y escalables para manejar este desafío de grandes datos. Este proyecto se centra en el almacén de valores-clave distribuidos, una solución comúnmente adoptada para ampliar el almacenamiento de datos.
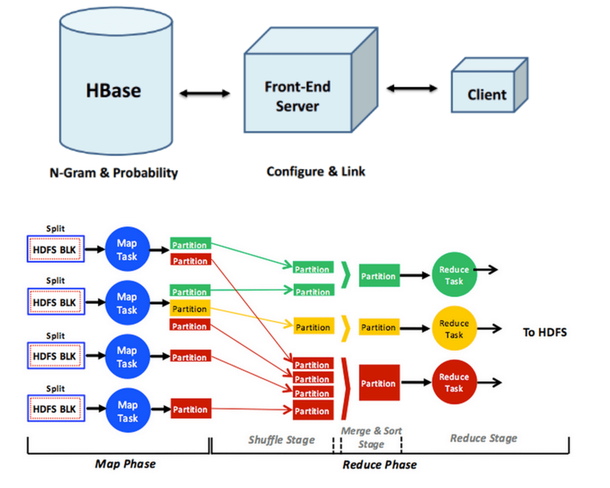
Predictor de texto de entrada y Autocompletado de Word
Para este proyecto, construí mi propio predictor de texto de entrada, similar a los que puede haber visto en las consultas de búsqueda de Google Instant. Construí este predictor de texto de entrada usando un corpus de texto. Los pasos necesarios para construir este predictor de texto de entrada son:
Dado un corpus de texto, genere una lista de n-grams, que es simplemente una lista de frases en un corpus de texto con sus conteos correspondientes.
Genere un modelo de lenguaje estadístico usando n-grams. El modelo de lenguaje estadístico contiene la probabilidad de que aparezca una palabra después de una frase.
Cree una interfaz de usuario para el predictor de texto de entrada, de modo que cuando se escriba una palabra o frase, la siguiente palabra pueda predecirse y mostrarse al usuario utilizando el modelo de lenguaje estadístico.
-822x1027-612w.jpg)
Línea de tiempo de redes sociales con backends heterogéneos(MySQL RDS, HBase, MongoDB)
Guión
Unas semanas después de que comenzó a trabajar en los sistemas de bases de datos en Carnegie SoShall, el Gerente de Proyecto notó su excelencia en la implementación de sistemas de almacenamiento escalables y decidió asignarle una tarea independiente que exploraría nuevas oportunidades para su empresa. Esto significa que trabajará con una mentalidad de inicio.
Sus proyectos anteriores lo equiparon con un útil conjunto de herramientas para el análisis de datos, sistemas de archivos distribuidos, servidores web y técnicas de programación simultáneas. Además, mientras trabajó con los datos de música, se dio cuenta de grandes oportunidades de comercialización en la industria del entretenimiento. Después de una investigación sobre un par de comunidades en línea donde la gente habla sobre los medios de entretenimiento, te das cuenta de que la gente está buscando una aplicación de redes sociales distintiva y emocionante con un tema sobre películas. Decide crear una aplicación atractiva y extraordinaria con este tema.
Usted ha elegido CinemaChat como el nombre de su aplicación. Al revisar cómo WhatsApp, Instagram y más equipos construyeron productos exitosos mediante la perforación a través de exactamente una función enfocada, limitará su alcance de desarrollo al tema de una red social para películas. La autenticación de usuario y las redes sociales son elementos obligatorios y, más allá de eso, su característica principal es permitir a los usuarios compartir películas y reseñas de películas. Después de una tormenta de ideas, concluyó que incluso la creación de una aplicación única terminaría con el mantenimiento de numerosos tipos de datos. Como cuestión de hecho, no existe una base de datos omnipotente que funcione perfectamente en el back-end. Por lo tanto, exploró varias opciones de almacenamiento de datos y se dio cuenta de que una combinación de tres sistemas de almacenamiento de datos satisfaría sus necesidades, siempre y cuando se presente un diseño de esquema adecuado para cada uno de ellos.