









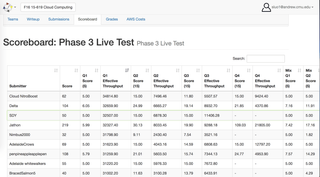
Sistema Big Data Analytics no AWS Cloud(Java, AWS, MapReduce, HBase, MySQL)
◈ Desenvolveu um serviço web de alto desempenho e tolerância a falhas para analisar mais de 1Tb de dados do Twitter com 4 consultas diferentes. Filtrou e transformou dados em bruto da AWS S3 para HBase e MySQL usando o MapReduce. Utilizou o balanceador de carga e as políticas de dimensionamento automático através dos contêineres API AWS Java e Docker para configuração.
◈ Aplicou mais de 5 métodos para otimizar o banco de dados e alcançou uma média de 27800 QPS (consultas por segundo) em um conjunto de dados contendo cerca de 200 milhões de registros com recursos muito limitados.
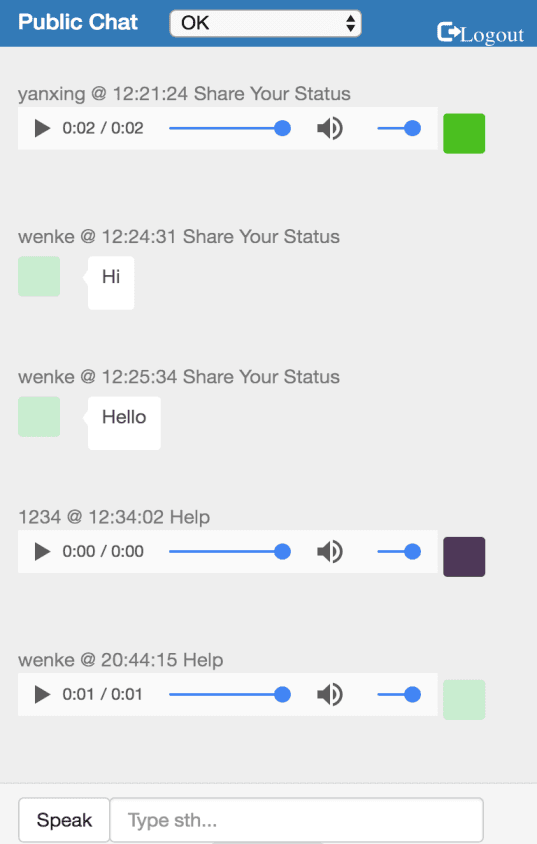
RESTful Emergency Social Network(Node.js, AngularJS, MongoDB, Heroku)
◈ Liderou uma equipe de 5 pessoas para desenvolver uma aplicação web em tempo real para comunicação sob desastres naturais.
◈ Criou uma aplicação web com o Node.js com o AngularJS, o MongoDB e implantou-o na nuvem de Heroku.
◈ Metodologia mista Scrum & Kanban seguidas com teste unitário, programação em pares e integração contínua.
◈ Desenvolveu um recurso de bate-papo por voz para melhorar a comunicação em tempo real e a técnica de decodificação base64 aplicada.

Serviço de correspondência de motorista de preços dinâmicos
Neste projeto, implementei um serviço de correspondência de drivers de preços dinâmicos com Kafka e Samza para simular e processar vários fluxos de dados de localização e eventos do driver UBER em streaming.
Cenário
O PittCabs é um novo aplicativo de cabine / viagem pessoal. Você é contratado para implementar a parte central do serviço, a de atender solicitações de clientes aos drivers disponíveis. Os aplicativos que aclamam a cabine como o Uber têm o driver enviar as atualizações de posição aproximadamente a cada 5 segundos, o que constitui um grande fluxo de dados. Uma maneira de lidar com as atualizações de posição é manter a atualização de uma loja de dados tradicional (MySQL / Hbase) com as posições e quando uma solicitação de piloto vier, procure a localização do piloto e combine o driver mais próximo ao cliente. Esta abordagem não é muito escalável mesmo com pisca e / ou replicação e é um desperdício, uma vez que o driver se move para uma nova posição 5 segundos depois, os dados antigos são inúteis. Sendo bem informado sobre as últimas tecnologias em nuvem, você decide usar o modelo de processamento de fluxo de computação, pois ele se encaixa muito bem no caso de uso.
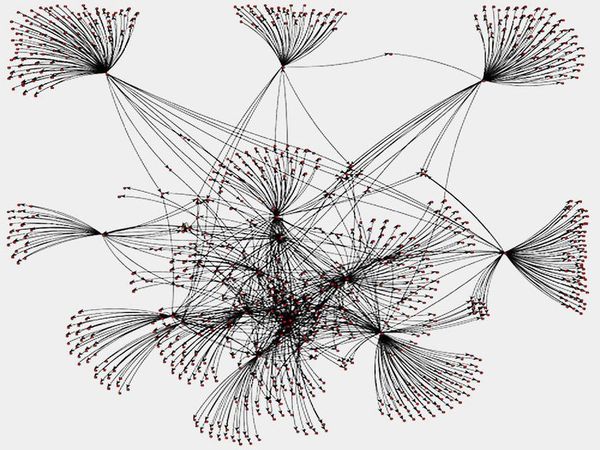
PageRank for Twitter Social Graph
(Scala, Spark, GraphX)
Neste projeto, usei Spark e GraphX para calcular o valor do PageRank para cada nó no gráfico social do Twitter.
Programação multi-threading e Consistência
Com o advento da internet, do comércio eletrônico e das mídias sociais, as organizações enfrentam uma explosão maciça da quantidade de dados que precisa ser manuseada diariamente. Não é incomum hoje em dia para grandes empresas de escala de internet ter que processar petabytes de dados diariamente. Armazenar, processar e analisar esses dados é um enorme desafio e há muito superou as capacidades de armazenamento, memória e computação de uma única máquina. Exigimos sistemas de armazenamento de dados distribuídos e escaláveis para lidar com esse grande desafio de dados. Este foco do projeto na loja de valores-chave distribuídos, uma solução comumente adotada para expandir o armazenamento de dados.
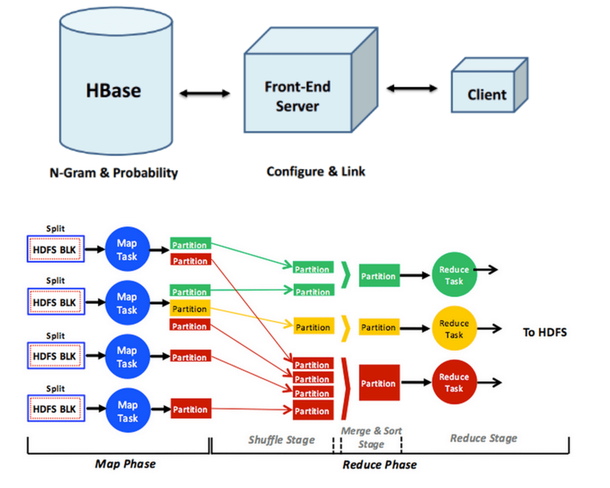
Predictor de Texto de Entrada e Conclusão Automática de Word
Para este projeto, eu criei meu próprio preditor de texto de entrada, semelhante ao que você tenha visto em consultas de pesquisa do Google Instant. Eu construí este preditor de texto de entrada usando um corpus de texto. As etapas envolvidas na construção deste preditor de texto de entrada são:
Dado um corpus de texto, gere uma lista de n-gramas, que é simplesmente uma lista de frases em um corpus de texto com suas contagens correspondentes.
Gerar um modelo de linguagem estatística usando os n-gramas. O modelo de linguagem estatística contém a probabilidade de uma palavra aparecer após uma frase.
Crie uma interface de usuário para o preditor de texto de entrada, de modo que quando uma palavra ou frase é digitada, a próxima palavra pode ser prevista e exibida para o usuário usando o modelo de linguagem estatística.
-822x1027-612w.jpg)
Linha de tempo de redes sociais com backups heterogêneos(MySQL RDS, HBase, MongoDB)
Cenário
Poucas semanas depois de começar a trabalhar nos sistemas de banco de dados da Carnegie SoShall, o Gerenciador de Projetos percebeu sua excelência na implementação de sistemas de armazenamento escaláveis e decidiu atribuir-lhe uma tarefa autônoma que exploraria novas oportunidades para sua empresa. Isso significa que você estará trabalhando com uma mentalidade inicial.
Seus projetos anteriores o equiparam com um útil conjunto de ferramentas para análise de dados, sistemas de arquivos distribuídos, servidores web e técnicas de programação concorrentes. Além disso, enquanto você trabalhou com os dados de música, você percebeu excelentes oportunidades de marketing no setor de entretenimento. Depois de uma investigação sobre algumas comunidades on-line onde as pessoas discutem mídia de entretenimento, você percebe que as pessoas estão procurando uma aplicação de rede social distinta e emocionante com um tema sobre filmes. Você decide construir uma aplicação atraente e extraordinária com este tema.
Você escolheu o CinemaChat como o nome da sua aplicação. Ao analisar como o WhatsApp, o Instagram e mais equipes também criaram produtos bem sucedidos, perfurando exatamente um recurso focado, você limitará seu escopo de desenvolvimento ao tema de uma rede social de filmes. A autenticação do usuário e as redes sociais são elementos obrigatórios e, além disso, sua principal característica é permitir que os usuários compartilhem filmes e avaliações de filmes. Após o brainstorming, você concluiu que mesmo a construção de um único aplicativo poderia acabar com a manutenção de vários tipos de dados. Na verdade, não existe uma base de dados omnipotente que funcione perfeitamente no backend. Portanto, você explorou várias opções de armazenamento de dados e percebeu que uma combinação de três sistemas de armazenamento de dados satisfaz suas necessidades, desde que você venha com um projeto de esquema apropriado para cada um deles.