









AWS云上的大数据分析系统(Java,AWS,MapReduce,HBase,MySQL)
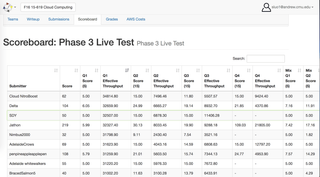
◈开发了一个高性能,容错的Web服务,用4种不同的查询分析1TB以上的Twitter数据。使用MapReduce将原始数据从AWS S3过滤并转换为HBase和MySQL。通过AWS Java API和Docker容器使用负载平衡器和自动扩展策略进行配置。
◈应用5种以上的方法对数据库进行优化,对包含资源非常有限的约2亿条记录的数据集实现平均27800 QPS(查询每秒)。
RESTful紧急社交网络(Node.js,AngularJS,MongoDB,Heroku)
◈带领一个5人小组开发自然灾害下的实时网络应用程序。
◈使用AngularJS,MongoDB构建Node.js支持的Web应用程序并将其部署到Heroku云中。
◈遵循Scrum和看板的混合方法学与单元测试,配对编程和持续集成。
◈开发了语音聊天功能,以更好的实时通信和应用base64解码技术。

动态定价驾驶员匹配服务
在这个项目中,我实施了与Kafka和Samza的动态定价的驾驶员匹配服务,以流的方式模拟和处理多个UBER驾驶员位置和事件数据流。
脚本
PittCabs是即将推出的私人出租车/相机应用程序。您被聘用来实现服务的核心部分,即将客户端请求匹配到可用的驱动程序。像Uber这样的驾驶室应用程序大概每5秒钟就会发送一次位置信息,这就形成了大量的数据流。处理位置更新的一种方法是不断更新传统的数据存储(MySQL / Hbase)的位置和骑手请求时,查找骑手的位置,并匹配最近的驱动程序与客户端。即使在分片和/或复制的情况下,这种方法的可扩展性也不是很高,并且是浪费的,因为一旦司机在5秒后移动到新的位置,旧的数据就没用了。对最新的云技术了如指掌,你决定使用计算流处理模型,因为它非常适合用例。
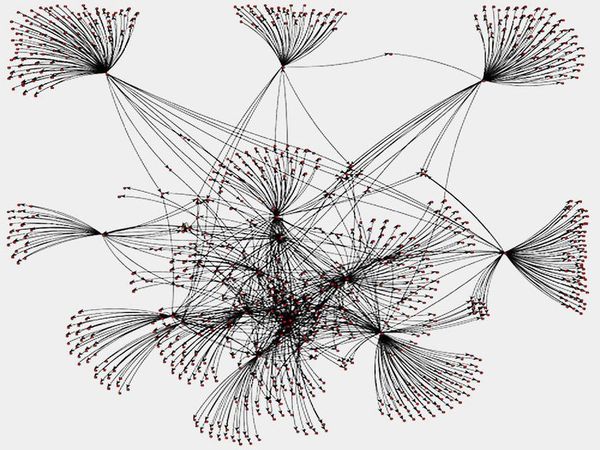
PageRank的Twitter社会图表
(Scala,Spark,GraphX)
在这个项目中,我使用Spark和GraphX来计算Twitter社交图中每个节点的PageRank值。
多线程编程和一致性
随着互联网,电子商务和社交媒体的出现,企业面临着日常需要处理的数据量的大幅度增长。大型互联网规模的公司现在每天都要处理PB级的数据,这种情况并不少见。存储,处理和分析这些数据是一个巨大的挑战,并且早已超越了单个机器的存储,存储和计算能力。我们需要分布式,可扩展的数据存储系统来处理这个大数据挑战。该项目专注于分布式键值存储,这是扩大数据存储的常用解决方案。
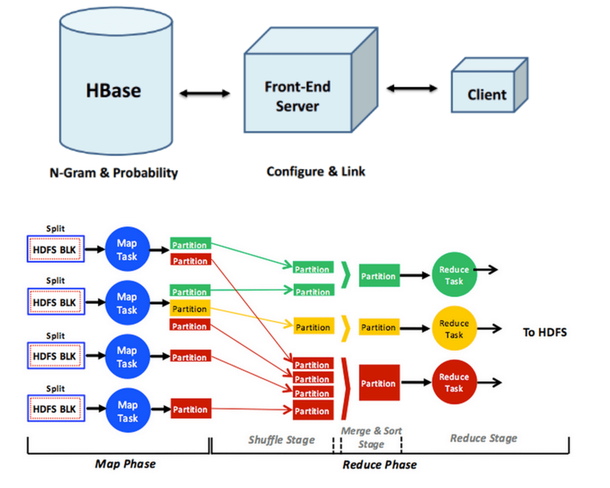
输入文本预测和字自动完成
对于这个项目,我建立了自己的输入文本预测器,类似于您在Google即时搜索查询中看到的预测器。我使用文本语料库构建了这个输入文本预测器。构建这个输入文本预测器的步骤是:
给定一个文本语料库,生成一个n-gram列表,这个列表只是文本语料库中的短语列表及其相应的计数。
使用n-gram生成统计语言模型。统计语言模型包含一个词语出现在词组之后的概率。
为输入文本预测器创建一个用户界面,以便在输入单词或短语时,可以使用统计语言模型预测下一个单词并将其显示给用户。
-822x1027-612w.jpg)
具有异构后端的社交网络时间表(MySQL RDS,HBase,MongoDB)
脚本
在Carnegie SoShall开始工作数周之后,项目经理注意到您在实施可扩展存储系统方面的卓越表现,并决定为您分配一个独立的任务,为您的企业探索新的机会。这意味着你将以创业思维开展工作。
您以前的项目为您提供了一个方便的数据分析工具包,分布式文件系统,Web服务器和并发编程技术。另外,在您使用音乐数据的同时,您还可以在娱乐行业中获得巨大的营销机会。在对一些人们讨论娱乐媒体的在线社区进行调查后,你会发现人们正在寻找一个以电影为主题的独特而令人兴奋的社交应用程序。你决定用这个主题来建立一个有吸引力和非凡的应用程序。
您选择了CinemaChat作为您的应用程序的名称。通过回顾WhatsApp,Instagram以及更多类似的团队,通过精确研究一个重点功能来构建成功的产品,您将把发展的范围局限于电影社交网络的主题。用户认证和社交网络是必备元素,除此之外,您的核心功能是让用户分享电影和电影评论。经过头脑风暴,你得出结论,即使建立这样一个单一的应用程序,将最终维护多种类型的数据。事实上,没有一个万能的数据库可以在后端完美运行。因此,您研究了多个数据存储选项,并意识到三个数据存储系统的组合可以满足您的需求,只要您为每个存储系统提供适当的模式设计即可。