









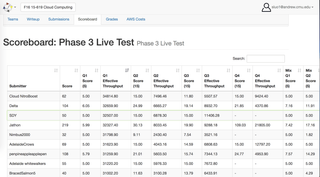
AWSクラウド上のビッグデータ分析システム(Java、AWS、MapReduce、HBase、MySQL)
◈4TBのクエリーで1TB以上のTwitterデータを分析する高性能のフォールトトレラントWebサービスを開発。 MapReduceを使用して、AWS S3からHBaseおよびMySQLにフィルタリングされ、変換された生データ。設定用のAWS Java APIおよびDockerコンテナによるロードバランサおよび自動スケーリングポリシーの利用。
◈データベースを最適化するために5つ以上のメソッドを適用し、リソースが非常に限られた約2億のレコードを含むデータセットで平均27800のQPS(1秒あたりのクエリ)を達成しました。
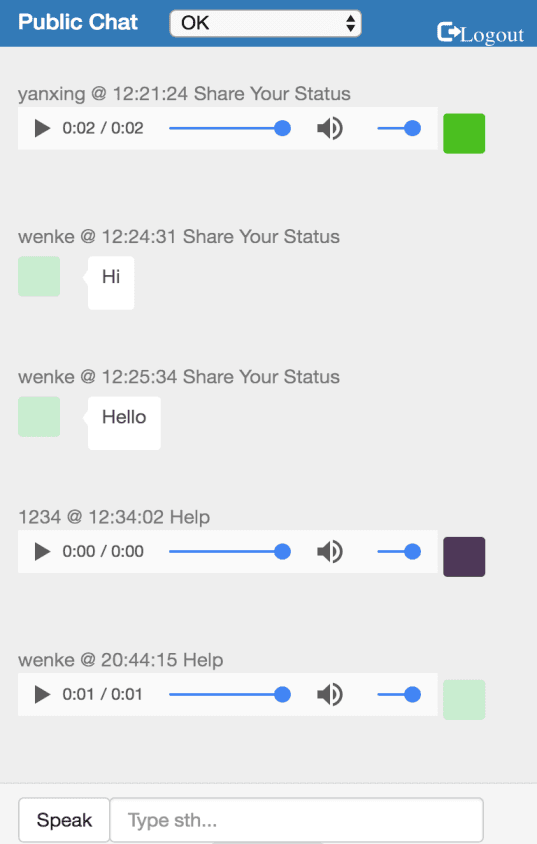
RESTful緊急ソーシャルネットワーク(Node.js、AngularJS、MongoDB、Heroku)
◈自然災害時のコミュニケーションのためのリアルタイムWebアプリケーションを開発するための5人チームを指導しました。
◈AngularJS、MongoDBでNode.jsを動力とするWebアプリケーションを構築し、Herokuクラウドに展開しました。
◈単体テスト、ペアプログラミング、連続的な統合を伴うスクラムとカンバンの混合方法に従った。
◈リアルタイムコミュニケーションをより良くするためのボイスチャット機能を開発し、ベース64デコード技術を適用しました。

動的料金設定ドライバマッチングサービス
このプロジェクトでは、KafkaとSamzaとの動的価格設定のドライバマッチングサービスを実装して、UBERドライバの複数のストリームとイベントデータをストリーミング形式でシミュレートして処理しました。
シナリオ
PittCabsは今後のプライベートタクシー/乗車券アプリです。あなたはサービスの中核部分を実装するために雇われ、利用可能なドライバに一致するクライアント要求を実装します。 Uberのようなキャビンを呼びかけるアプリは、ドライバーに約5秒ごとに位置更新を送信し、大きなデータストリームを形成させます。ポジションの更新を処理する1つの方法は、従来のデータストア(MySQL / Hbase)をポジションで更新し続け、ライダーの要求が来たら、ライダーの位置を調べて、最も近いドライバをクライアントに一致させることです。このアプローチは、シャーディングやレプリケーションであってもスケーラビリティがあまり高くなく、5秒後に新しい位置に移動すると古いデータは役に立たないため、無駄です。最新のクラウド技術を十分に理解しているので、ユースケースに非常によく合うので、計算のストリーム処理モデルを使用することにします。
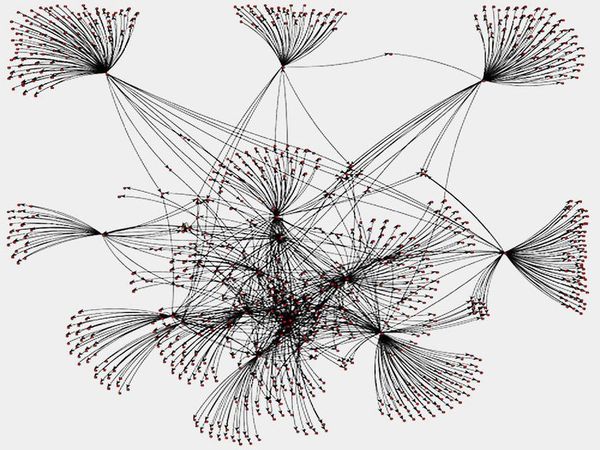
TwitterソーシャルグラフのPageRank
(Scala、Spark、GraphX)
このプロジェクトでは、SparkとGraphXを使ってTwitterソーシャルグラフの各ノードのPageRank値を計算しました。
マルチスレッドプログラミングと一貫性
インターネット、電子商取引、ソーシャルメディアの登場により、企業は毎日処理する必要のあるデータ量が爆発的に増加しています。大規模インターネット企業が毎日ペタバイトのデータを処理しなければならないことは珍しくありません。このデータの保存、処理、分析は膨大な課題であり、単一のマシンのストレージ、メモリ、コンピューティングの能力をはるかに上回っています。我々は、この大きなデータの課題に対応するために、分散型のスケーラブルなデータストレージシステムを必要としています。このプロジェクトは、分散型のキーバリューストアに焦点を当てています。これは、データストレージを拡大するために一般的に採用されているソリューションです。
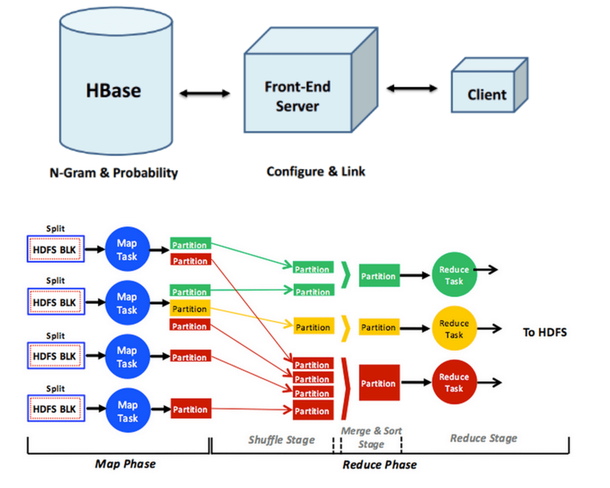
入力テキスト・プレディクタとワード自動補完
このプロジェクトでは、Googleインスタント検索クエリで見たような入力テキストプレディクタを作成しました。テキストコーパスを使用してこの入力テキスト予測子を作成しました。この入力テキストプレディクタを構築する手順は次のとおりです。
テキストコーパスが与えられた場合、n-gramのリストを生成します。これは、テキストコーパス内のフレーズのリストと、それに対応するカウントが含まれています。
nグラムを使用して統計言語モデルを生成します。統計的言語モデルは、フレーズの後に出現する確率を含む。
単語または句が入力されると、統計言語モデルを使用して次の単語を予測してユーザーに表示できるように、入力テキスト予測子のユーザーインターフェイスを作成します。
-822x1027-612w.jpg)
異機種バックエンドによるソーシャルネットワーキングのタイムライン(MySQL RDS、HBase、MongoDB)
シナリオ
Carnegie SoShallのデータベースシステムで作業を開始してから数週間後、Project Managerはスケーラブルなストレージシステムの実装に優れていることに気付き、企業の新しい機会を探るスタンドアロンのタスクを割り当てることに決めました。これは、あなたがスタートアップの考え方に取り組むことを意味します。
以前のプロジェクトでは、データ分析、分散ファイルシステム、Webサーバー、並行プログラミング技術のための便利なツールキットが用意されていました。また、音楽データを扱っている間に、エンターテイメント業界で大きなマーケティングの機会を得ました。人々がエンターテイメントメディアについて話し合ういくつかのオンラインコミュニティを調査したところ、人々は映画に関するテーマを持つ独特でエキサイティングなソーシャルネットワーキングアプリケーションを探していることに気づきました。あなたは、このテーマで魅力的で特別なアプリケーションを構築することに決めました。
あなたは、あなたのアプリケーションの名前としてCinemaChatを選択しました。 WhatsApp、Instagramなどのチームが正確に1つの焦点を絞った機能を掘り下げて成功した製品を構築した方法を見直すことで、開発の範囲を映画のソーシャルネットワークのテーマに限定することができます。ユーザー認証とソーシャルネットワーキングは必須要素であり、それ以外にも、ユーザーが映画や映画のレビューを共有できるようにすることが重要です。ブレインストーミングの後、そのような単一のアプリケーションを構築するだけでも、多数のタイプのデータを維持することになると結論付けました。実際、バックエンドで完全に機能する全能データベースは存在しません。したがって、複数のデータ・ストレージ・オプションを検討し、3つのデータ・ストレージ・システムを組み合わせることで、それぞれのスキーマ設計が適切である限り、ニーズを満たすことができます。