









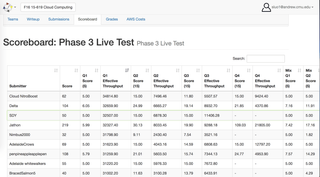
एडब्लूएस बादल पर बिग डेटा एनालिटिक्स सिस्टम(जावा, एडब्ल्यूएस, मैपरेड्यूस, एचबीज़, मायएसक्यूएल)
With 4 विभिन्न प्रश्नों के साथ 1TB ट्विटर डेटा का विश्लेषण करने के लिए एक उच्च प्रदर्शन, दोष-सहिष्णु वेब सेवा विकसित की है। MapReduce का उपयोग करते हुए AWS S3 से HBase और MySQL के कच्चे डेटा को छान लिया और बदल दिया। कॉन्फ़िगरेशन के लिए एडब्लूएस जावा एपीआई और डॉकर कंटेनर के माध्यम से लोड बैलेंसर और ऑटो स्केलिंग नीतियों का उपयोग किया गया
The डेटाबेस को अनुकूलित करने के लिए 5 से अधिक तरीकों को लागू किया और एक सीमित डाटाबेस पर 27800 क्यूपीएस (प्रति सेकंड प्रश्न) हासिल किया, जिसमें बहुत सीमित संसाधनों के साथ 200 मिलियन रिकॉर्ड थे।
शोकपूर्ण इमरजेंसी सोशल नेटवर्क(नोड। जेएस, एंजरीजेएस, मोंगोडीबी, हेरोकू)
Under प्राकृतिक आपदाओं के तहत संचार के लिए वास्तविक समय वेब अनुप्रयोग विकसित करने के लिए 5 व्यक्ति की टीम का नेतृत्व किया।
With AngularJS, MongoDB के साथ एक नोड। जेएस संचालित वेब अनुप्रयोग बनाया और हेरोक्यू बादल पर तैनात किया।
◈ यूनिट टेस्ट, जोड़ी प्रोग्रामिंग और निरंतर एकीकरण के साथ Scrum और Kanban मिश्रित पद्धति का पालन किया।
The रीयल-टाइम संचार को बेहतर बनाने और base64 decode तकनीक को लागू करने के लिए एक ध्वनि चैट सुविधा विकसित की।

गतिशील-मूल्य निर्धारण ड्रायवर मिलान सेवा
इस प्रोजेक्ट में, मैंने काफ़का और समजा के साथ एक गतिशील-मूल्य निर्धारण चालक मिलान सेवा को कार्यान्वित किया है ताकि यूबेर ड्राइवर स्थान के कई धाराओं और स्ट्रीमिंग फ़ैशन के ईवेंट डेटा को अनुकरण और संसाधित किया जा सके।
परिदृश्य
पिटकैब एक आगामी निजी टैक्सी / राइडशेयर ऐप है आप सेवा के मुख्य भाग को कार्यान्वित करने के लिए काम पर रखा है, जो कि उपलब्ध ड्राइवरों से मिलते-जुलते क्लाइंट अनुरोधों का है। कैब में उबर की तरह एप्लिकेशन हैं, जैसे चालक को हर 5 सेकंड में स्थिति अपडेट भेजता है, जो डेटा की एक बड़ी धारा बनाता है। स्थिति अद्यतनों को संभालने का एक तरीका एक पारंपरिक डाटा स्टोर (MySQL / Hbase) को स्थिति के साथ अद्यतन करना है और जब एक सवार अनुरोध किया जाता है, तो सवार के स्थान को देखें और क्लाइंट को निकटतम ड्राइवर से मेल करें। इस दृष्टिकोण को कंजूस और / या प्रतिकृति के साथ भी बहुत अधिक स्केलेबल नहीं है और एक बार चालक ने 5 सेकंड के बाद एक नई स्थिति में कदम रखा है, इसलिए पुराने डेटा बेकार है। नवीनतम क्लाउड प्रौद्योगिकियों को अच्छी तरह से सूचित किया जा रहा है, आप गणना के स्ट्रीम प्रसंस्करण मॉडल का उपयोग करने का निर्णय लेते हैं क्योंकि यह उपयोग केस बहुत अच्छी तरह से फिट बैठता है।
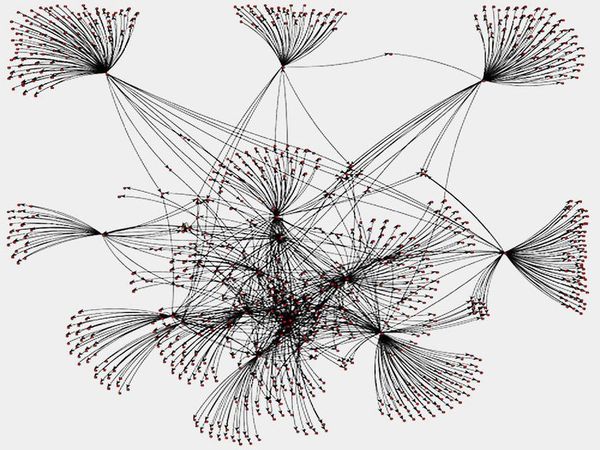
चहचहाना सामाजिक ग्राफ के लिए PageRank
(स्काला, स्पार्क, ग्राफएक्स)
इस परियोजना में, मैंने चहचहाना सामाजिक ग्राफ में प्रत्येक नोड के लिए PageRank मूल्य की गणना करने के लिए स्पार्क और ग्राफिक्स का उपयोग किया था।
मल्टी थ्रेडिंग प्रोग्रामिंग और संगतता
इंटरनेट, ई-कॉमर्स और सोशल मीडिया के आगमन के साथ, संगठनों को डेटा की मात्रा में बड़े पैमाने पर विस्फोट का सामना करना पड़ रहा है, जिन्हें दैनिक रूप से संभालना आवश्यक है। इन दिनों बड़े इंटरनेट-स्तरीय कंपनियों के लिए डेटा के पेटबाइट्स को दैनिक आधार पर संसाधित करना अनिवार्य नहीं है। इस डेटा को भंडारण, प्रसंस्करण और विश्लेषण करना एक बड़ी चुनौती है और उसने एक मशीन की भंडारण, मेमोरी और कंप्यूटिंग क्षमताओं को पार किया है। हमें इस बड़े डेटा चुनौती को संभालने के लिए वितरित, स्केलेबल डेटा संग्रहण सिस्टम की आवश्यकता है वितरित कुंजी-मूल्य स्टोर पर यह परियोजना फ़ोकस, डेटा संग्रहण को स्केल करने के लिए एक सामान्यतः अपनाया गया समाधान।
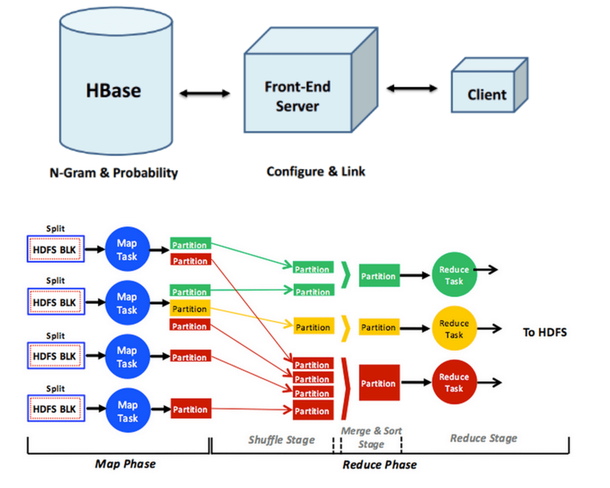
इनपुट टेक्स्ट प्रिविक्षक और शब्द स्वत: -पूर्णता
इस परियोजना के लिए, मैंने अपना स्वयं का इनपुट टेक्स्ट भविष्यवक्ता बनाया, जैसा आप Google इंस्टेंट खोज क्वेरी में देख सकते हैं। मैंने एक पाठ कॉर्पस का उपयोग करके इस इनपुट पाठ भविष्यवक्ता को बनाया है I इस इनपुट पाठ भविष्यवक्ता के निर्माण में शामिल कदम निम्न हैं:
एक टेक्स्ट कॉर्पस को देखते हुए, एन-ग्राम की एक सूची तैयार की जाती है, जो कि पाठ सूची में वाक्यांशों की एक सूची होती है, जो उनके संबंधित गणनाओं के साथ होती है।
एन-ग्राम का इस्तेमाल करते हुए एक सांख्यिकीय भाषा मॉडल उत्पन्न करें सांख्यिकीय भाषा मॉडल में वाक्यांश के बाद प्रदर्शित होने वाले शब्द की संभावना है।
इनपुट टेक्स्ट प्रिविक्टर के लिए यूजर इंटरफेस बनाएं, ताकि जब कोई शब्द या वाक्यांश टाइप किया जाए, तो अगले शब्द को भविष्यवाणी की जा सकती है और उपयोगकर्ता को सांख्यिकीय भाषा मॉडल का उपयोग कर दिखाया जा सकता है।
-822x1027-612w.jpg)
हिस्टोजिनेस बॅकेंड के साथ सोशल नेटवर्किंग टाइमलाइन(MySQL आरडीएस, एचबीज़, मोंगोडीबी)
परिदृश्य
कार्नेगी सोशल में डेटाबेस सिस्टम पर काम करना शुरू करने के कुछ हफ्तों के बाद, प्रोजेक्ट मैनेजर ने स्केलेबल स्टोरेज सिस्टम को कार्यान्वित करने में आपकी उत्कृष्टता को देखा और आपको एक स्टैंडअलोन कार्य प्रदान करने का निर्णय लिया जो आपके उद्यम के लिए नए अवसर तलाश सके। इसका मतलब यह है कि आप एक स्टार्टअप मानसिकता के साथ काम करेंगे।
आपकी पिछली परियोजनाओं में डेटा एनालिटिक्स, वितरित फाइल सिस्टम, वेब सर्वर और समवर्ती प्रोग्रामिंग तकनीकों के लिए एक आसान टूलकिट प्रदान की गई थी। इसके अलावा, जब आप संगीत डेटा के साथ काम करते थे, तो आपको मनोरंजन उद्योग में महान विपणन अवसरों का एहसास हुआ। कुछ ऑनलाइन समुदायों की जांच के बाद जहां लोग मनोरंजन मीडिया पर चर्चा करते हैं, आपको लगता है कि लोग फिल्मों के विषय के साथ एक विशिष्ट और रोमांचक सोशल नेटवर्किंग एप्लिकेशन की तलाश में हैं। आप इस विषय के साथ एक आकर्षक और असाधारण अनुप्रयोग बनाने का निर्णय लेते हैं।
आपने सिनेमाआर्ट को अपने आवेदन के नाम के रूप में चुना है कैसे व्हाट्सएप, इंस्टाग्राम और अधिक तरह की टीमों की समीक्षा करके, एक विशेष फीचर के माध्यम से ड्रिलिंग द्वारा सफल उत्पादों का निर्माण किया, आप अपने विकास के दायरे को सिनेमा के लिए एक सोशल नेटवर्क के विषय में सीमित कर सकते हैं। उपयोगकर्ता प्रमाणीकरण और सोशल नेटवर्किंग अनिवार्य तत्व हैं, और इसके अलावा, आपकी मुख्य सुविधा उपयोगकर्ताओं को मूवी और फिल्म समीक्षा साझा करने देती है। बुद्धिशीलता के बाद, आपने निष्कर्ष निकाला है कि यहां तक कि एक ही आवेदन का निर्माण भी कई प्रकार के डेटा को बनाए रखने में होगा। तथ्य की बात के रूप में, सर्वव्यापी डेटाबेस के रूप में ऐसी कोई चीज नहीं है जो बैकएंड में पूरी तरह से कार्य करेगी। इसलिए, आपने कई डेटा संग्रहण विकल्पों का पता लगाया और यह महसूस किया कि तीन डेटा संग्रहण प्रणालियों का संयोजन आपकी आवश्यकताओं को पूरा करेगा, जब तक आप उनमें से प्रत्येक के लिए एक उचित स्कीमा डिज़ाइन के साथ आएंगे।