









NASA-Funded Project(Java, Play Framework, MySQL, Ebean, Git)
◈ Cooperated with NASA and worked as a full-stack engineer to develop an online platform for scientists to record, share and analyze scientific data using Java Play Framework.
◈ Provided RESTful APIs at backend side, designed and developed frontend Web UI using jQuery and Bootstrap.
◈ Applied several design patterns to optimize the software architecture and used Docker for configuration.
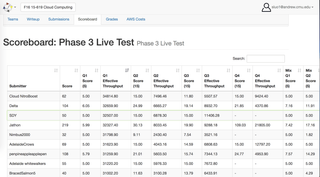
Big Data Analytics System on AWS Cloud(Java, AWS, MapReduce, HBase, MySQL)
◈ Developed a high performance, fault-tolerant web service to analyze over 1TB Twitter data with 4 different queries. Filtered and transformed raw data from AWS S3 to HBase and MySQL using MapReduce. Utilized load balancer and auto scaling policies via AWS Java API and Docker containers for configuration.
◈ Applied more than 5 methods to optimize the database and achieved an average of 27800 QPS (queries per second) on a dataset containing about 200 million records with very limited resources.
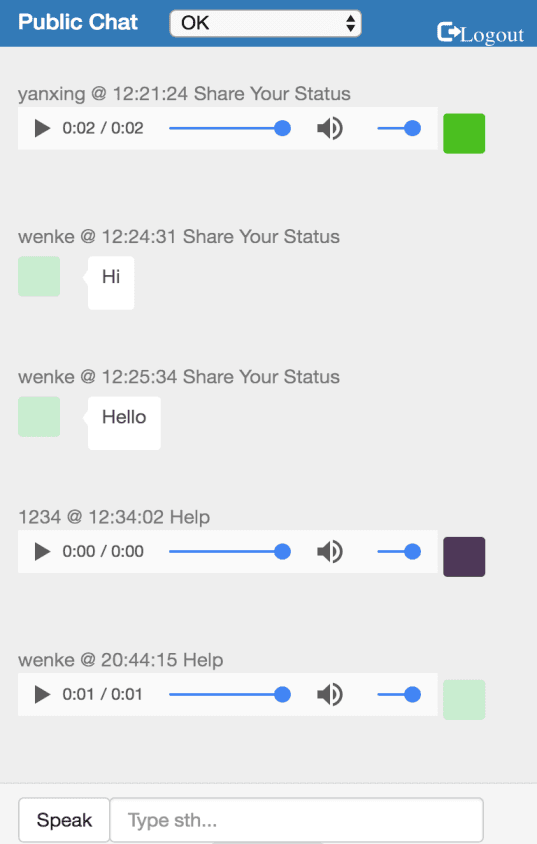
RESTful Emergency Social Network (Node.js, AngularJS, MongoDB, Heroku)
◈ Led a 5-person team to develop a real-time web application for communication under natural disasters.
◈ Built a Node.js powered web application with AngularJS, MongoDB and deployed it on Heroku cloud.
◈ Followed Scrum & Kanban mixed methodology with unit test, pair programming and continuous integration.
◈ Developed a voice chat feature to better the real-time communication and applied base64 decode technique.

Dynamic-pricing Driver Matching Service
In this project, I implemented a dynamic-pricing Driver Matching Service with Kafka and Samza to simulate and process multiple streams of UBER driver location and events data in streaming fashion.
Scenario
PittCabs is an upcoming private cab/rideshare app. You are hired to implement the core part of the service, that of matching client requests to available drivers. Cab hailing apps like Uber have the driver send position updates roughly every 5 seconds which forms a large stream of data. One way to handle the position updates is to keep updating a traditional data store (MySQL/Hbase) with the positions and when a rider request comes in, look up the location of the rider and match the closest driver to the client. This approach is not very scalable even with sharding and/or replication and is wasteful since once the driver has move to a new position 5 seconds later, the old data is useless. Being well informed on the latest cloud technologies, you decide to use the stream processing model of computation since it fits the use case very well.
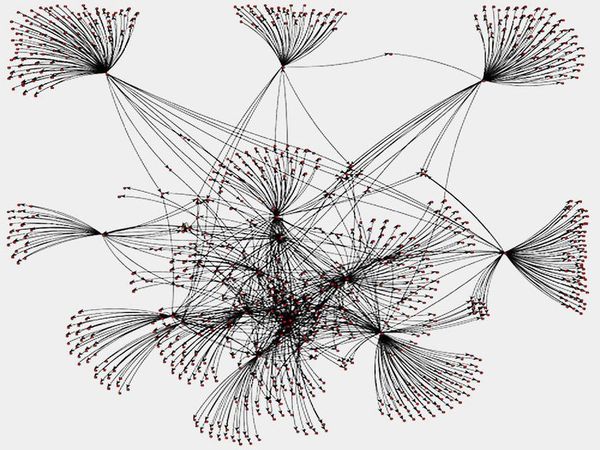
PageRank for Twitter Social Graph
(Scala, Spark, GraphX)
In this project, I utilized Spark as well as GraphX to compute the PageRank value for each node in the Twitter social graph.
Multi-threading programming and Consistency
With the advent of the internet, e-commerce and social media, organizations are facing a massive explosion in the amount of data that needs to be handled daily. It is not uncommon these days for large internet-scale companies to have to process petabytes of data on a daily basis. Storing, processing and analyzing this data is an enormous challenge and has long surpassed the storage, memory and computing capabilities of a single machine. We require distributed, scalable data storage systems to handle this big-data challenge. This project focus on distributed key-value store, a commonly adopted solution for scaling up data storage.
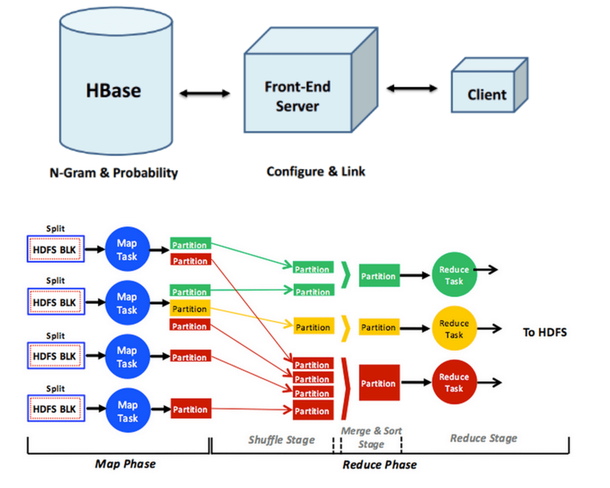
Input Text Predictor and Word Auto-Completion
For this project, I built my own input text predictor, similar to ones you may have seen in Google Instant search queries. I built this input text predictor using a text corpus. The steps involved in building this input text predictor are:
Given a text corpus, generate a list of n-grams, which is simply a list of phrases in a text corpus with their corresponding counts.
Generate a statistical language model using the n-grams. The statistical language model contains the probability of a word appearing after a phrase.
Create a user interface for the input text predictor, so that when a word or phrase is typed, the next word can be predicted and displayed to the user using the statistical language model.
-822x1027-612w.jpg)
Social Networking Timeline with Heterogeneous Backends(MySQL RDS, HBase, MongoDB)
Scenario
A few weeks after you started to work on the database systems at Carnegie SoShall, the Project Manager noticed your excellence in implementing scalable storage systems and decided to assign you a standalone task that would explore new opportunities for your enterprise. This means that you will be working with a startup mindset.
Your previous projects equipped you with a handy toolkit for data analytics, distributed file systems, web servers and concurrent programming techniques. Also, while you worked with the music data, you realized great marketing opportunities in the entertainment industry. After an investigation into a couple of online communities where people discuss entertainment media, you realize that people are looking for a distinctive and exciting social networking application with a theme on movies. You decide to build an attractive and extraordinary application with this theme.
You have chosen CinemaChat as the name of your application. By reviewing how WhatsApp, Instagram and more likewise teams built successful products by drilling through exactly one focused feature, you will confine your scope of development to the theme of a social network for movies. User authentication and social networking are compulsory elements and, beyond that, your core feature is to let users share movies and movie reviews. After brainstorming, you concluded that even building such a single application would end up with maintaining numerous types of data. As a matter of fact, there is no such thing as an omnipotent database that would function perfectly in the backend. Therefore, you explored multiple data storage options and realized that a combination of three data storage systems would satisfy your needs, as long as you come up with a proper schema design for each of them.