









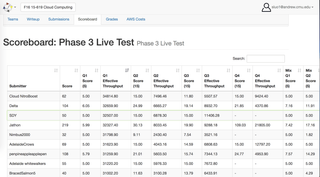
AWS 클라우드의 빅 데이터 분석 시스템(Java, AWS, MapReduce, HBase, MySQL)
◈ 4TB의 쿼리로 1TB 이상의 트위터 데이터를 분석 할 수있는 고성능의 내결함성 웹 서비스를 개발했습니다. MapReduce를 사용하여 AWS S3에서 HBase 및 MySQL로 필터링 및 변환 된 원시 데이터. 구성을 위해 AWS Java API 및 Docker 컨테이너를 통해로드 밸런서 및 자동 확장 정책 활용
◈ 데이터베이스를 최적화하기 위해 5 가지가 넘는 방법을 적용했으며, 자원이 매우 제한되어있는 약 2 억 개의 레코드가 포함 된 데이터 세트에서 평균 27800 개의 QPS (초당 쿼리)를 달성했습니다.
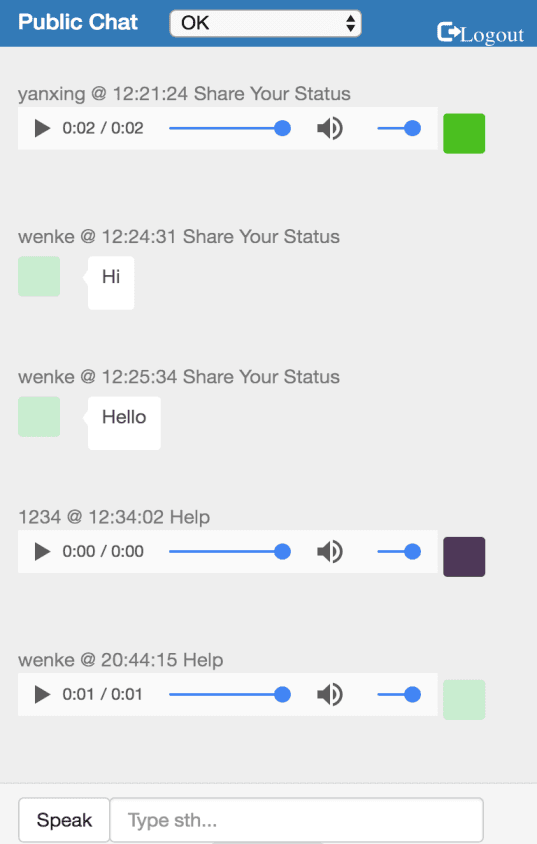
RESTful 비상 사태 네트워크(Node.js, AngularJS, MongoDB, Heroku)
◈ 자연 재해 발생시 의사 소통을위한 실시간 웹 응용 프로그램 개발을 위해 5 명으로 구성된 팀을 이끌었다.
◈ AngularJS, MongoDB와 함께 Node.js 구동 웹 어플리케이션을 구축하여 Heroku 클라우드에 전개했습니다.
◈ 단위 테스트, 쌍 프로그래밍 및 연속 통합을 통한 Scrum & Kanban 혼합 방법론을 따랐습니다.
◈ 실시간 통신 및 Base64 Decode 기술 적용을위한 음성 채팅 기능을 개발하였습니다.

동적 가격 드라이버 매칭 서비스
이 프로젝트에서 나는 카프카 (Kafka)와 삼자 (Samza)의 동적 가격 매칭 드라이버 매칭 서비스를 구현하여 스트리밍 방식으로 UBER 드라이버 위치 및 이벤트 데이터의 여러 스트림을 시뮬레이션하고 처리했습니다.
대본
PittCabs는 다가오는 개인 택시 / 라이드 쉐어 앱입니다. 서비스의 핵심 부분, 사용 가능한 드라이버에 대한 클라이언트 요청 일치 부분을 구현하기 위해 고용되었습니다. 우버 (Uber)와 같은 애호가들에게는 약 5 초마다 위치 업데이트가 전송되어 큰 데이터 스트림이 생성됩니다. 위치 업데이트를 처리하는 한 가지 방법은 기존 데이터 저장소 (MySQL / Hbase)를 위치로 업데이트하고 라이더 요청이 들어 왔을 때 라이더 위치를 검색하여 가장 가까운 드라이버를 클라이언트와 일치시키는 것입니다. 이 방법은 샤딩 및 / 또는 복제 작업을하더라도 확장 성이 뛰어나지 않으며 5 초 후에 드라이버가 새로운 위치로 이동하면 오래된 데이터는 쓸모가 없기 때문에 낭비입니다. 최신 클라우드 기술에 대해 잘 알고 있다면 유스 케이스에 매우 잘 맞기 때문에 계산의 스트림 처리 모델을 사용하기로 결정했습니다.
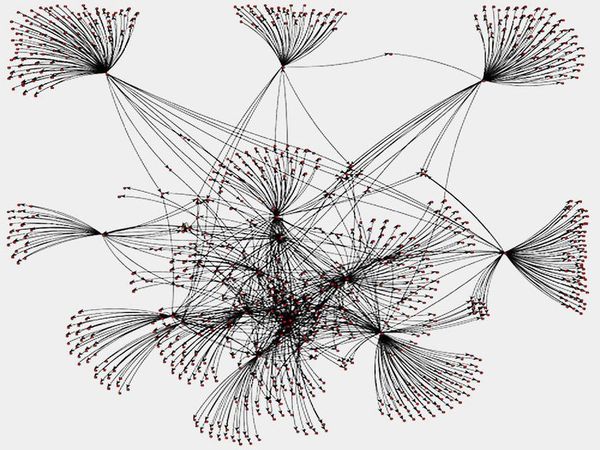
트위터 소셜 그래프 용 PageRank
(Scala, Spark, GraphX)
이 프로젝트에서 저는 Spark와 GraphX를 사용하여 Twitter 소셜 그래프에서 각 노드의 PageRank 값을 계산했습니다.
멀티 스레딩 프로그래밍 및 일관성
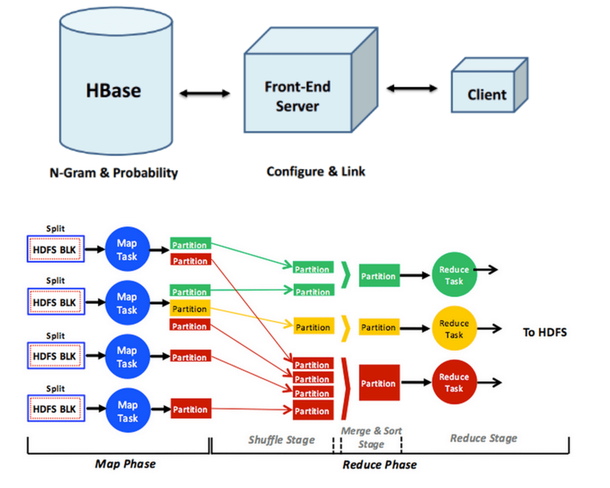
인터넷, 전자 상거래 및 소셜 미디어의 출현과 함께 조직에서는 매일 처리해야하는 데이터의 양이 급격히 증가하고 있습니다. 요즘 대규모 인터넷 기업이 매일 페타 바이트 단위의 데이터를 처리해야하는 경우는 드물지 않습니다. 이 데이터의 저장, 처리 및 분석은 엄청난 과제이며 단일 시스템의 저장, 메모리 및 컴퓨팅 기능을 오랫동안 능가 해 왔습니다. 우리는 이러한 큰 데이터 문제를 해결할 수있는 분산 형, 확장형 데이터 스토리지 시스템이 필요합니다. 이 프로젝트는 데이터 저장소를 확장하기 위해 일반적으로 채택 된 분산 키 - 값 저장소에 중점을 둡니다.
입력 텍스트 예측 자 및 단어 자동 완성
이 프로젝트의 경우 Google 순간 검색 쿼리에서 볼 수있는 것과 유사한 입력 텍스트 예측기를 직접 만들었습니다. 텍스트 코퍼스를 사용하여이 입력 텍스트 예측자를 만들었습니다. 이 입력 텍스트 예측자를 작성하는 단계는 다음과 같습니다.
텍스트 코퍼스가 주어지면 n 그램 목록을 생성합니다. n 그램 목록은 텍스트 코퍼스에서 해당 수와 함께 문구 목록 일뿐입니다.
n 그램을 사용하여 통계 언어 모델을 생성하십시오. 통계 언어 모델은 구문 뒤에 단어가 나타날 확률을 포함합니다.
단어 또는 구를 입력 할 때 다음 단어를 예측하여 통계 언어 모델을 사용하여 사용자에게 표시 할 수 있도록 입력 텍스트 예측기에 대한 사용자 인터페이스를 만듭니다.
-822x1027-612w.jpg)
이기종 백엔드가있는 소셜 네트워킹 타임 라인(MySQL RDS, HBase, MongoDB)
대본
Carnegie SoShall의 데이터베이스 시스템에서 작업을 시작한 몇 주 후, Project Manager는 확장형 스토리지 시스템을 구현하는 데있어 탁월한 성과를 얻었으며 기업에 새로운 기회를 모색 할 독립형 작업을 할당하기로 결정했습니다. 즉, 시작 사고 방식으로 작업하게됩니다.
이전 프로젝트는 데이터 분석, 분산 파일 시스템, 웹 서버 및 동시 프로그래밍 기술을위한 편리한 툴킷을 제공했습니다. 또한 음악 데이터를 작업하면서 엔터테인먼트 업계에서 훌륭한 마케팅 기회를 얻었습니다. 사람들이 엔터테인먼트 미디어에 대해 토론하는 몇 가지 온라인 커뮤니티에 대한 조사를 통해 사람들은 영화 테마와 함께 독특하고 흥미 진진한 소셜 네트워킹 응용 프로그램을 찾고 있음을 깨닫습니다. 이 테마로 매력적이고 특별한 응용 프로그램을 만들기로 결정했습니다.
응용 프로그램의 이름으로 CinemaChat을 선택했습니다. WhatsApp, Instagram 및 더 많은 팀이 정확하게 하나의 초점을 맞춘 기능을 통해 성공적인 제품을 제작 한 방법을 검토함으로써 개발 범위를 영화 용 소셜 네트워크의 테마로 한정 할 수 있습니다. 사용자 인증 및 소셜 네트워킹은 필수 요소이며, 그 외에 핵심 기능은 사용자가 영화 및 영화 리뷰를 공유 할 수 있도록하는 것입니다. 브레인 스토밍 후, 그러한 단일 응용 프로그램을 구축하더라도 수많은 유형의 데이터를 유지할 것이라고 결론을지었습니다. 사실, 백엔드에서 완벽하게 작동 할 수있는 전능 데이터베이스와 같은 것은 존재하지 않습니다. 따라서 여러 데이터 저장 옵션을 탐험하고 각각에 대해 적절한 스키마 디자인을 마련하는 한 세 가지 데이터 저장 시스템을 조합하여 사용자의 요구를 충족시킬 수 있다는 것을 깨달았습니다.